교육
AI 교육
AI 아이펠
- AI 심화
(사전모집)
AI 코어
- AI 기초
취준생 액티브러닝 캠프
액티브러닝 캠프
(모집중)
프론트엔드 개발자
(모집중)
백엔드 개발자
(모집중)
데이터 분석가
(사전모집)
데이터 사이언티스트
(사전모집)
직장인 액티브러닝 캠프
AI/LLM 서비스 개발
- 퇴근후 2시간으로 완성
(사전모집)
온라인 강의
전체보기
인기/추천강의
(할인중)
국비지원
(내일배움카드)
커뮤니티
모두모임
- 함께 성장하는 즐거움
LAB
- 모두의 열린 연구실
페이퍼샵
- 해외 학술 논문 지원
테크포임팩트
- 임팩트 기술 커뮤니티
무료 세미나
직장인 AI
- 직장인 대상 무료 교육
모두콘 2024
- AI for Next Impact
AI 기업 교육
블로그
스토리
교육
커뮤니티
무료 세미나
AI 기업 교육
블로그
스토리
로그인
로그인
아티클
모두연 인기
인공지능
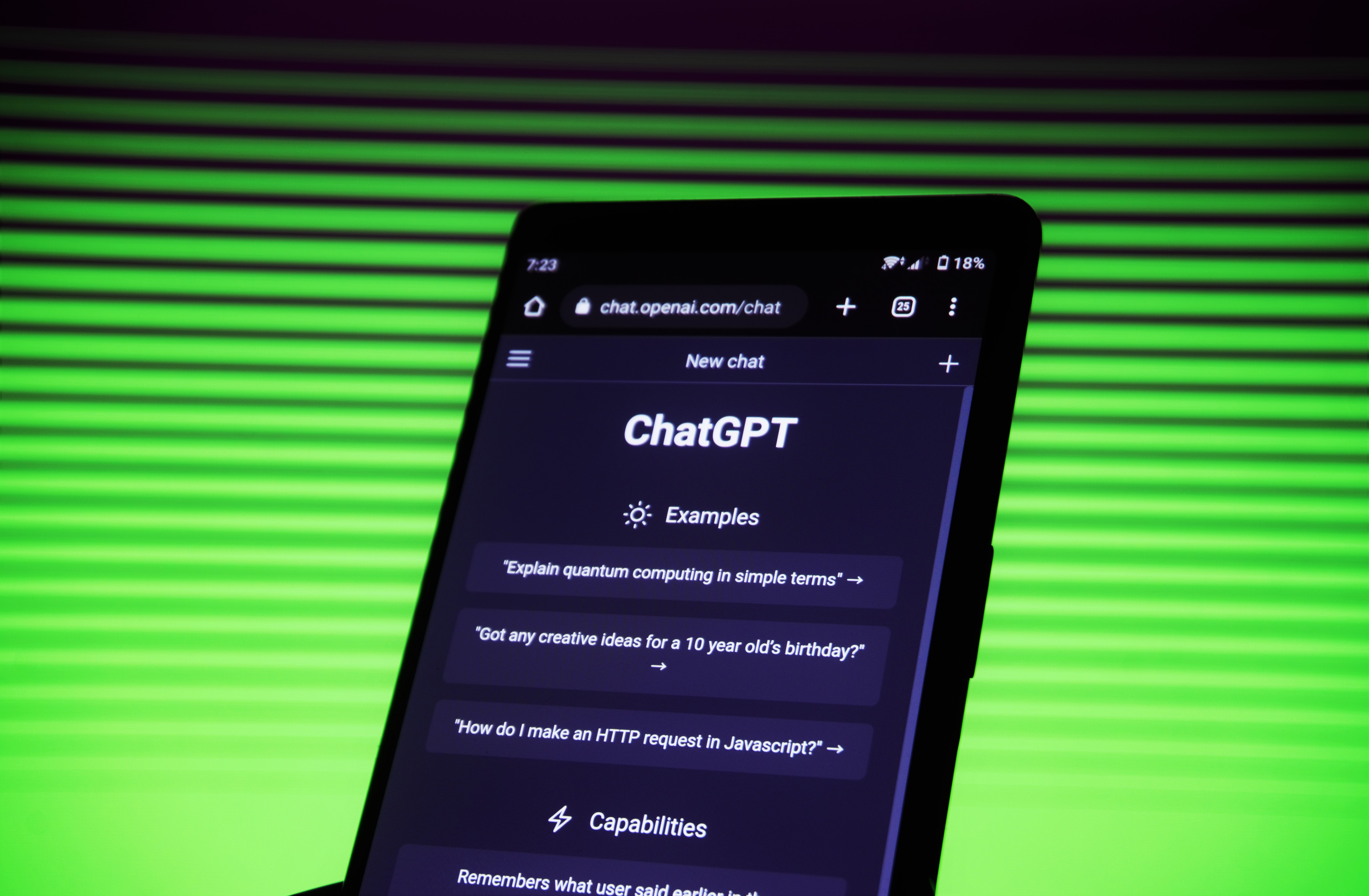
AI 리터러시 늘리기 : 박태웅의 AI 강의 리뷰
자기계발서는 싫지만 챗GPT와 인류의 미래는 알아야겠는 사람들을 위한 보편적이고 쉬운 책이 나왔습니다. 데이터 리터러시를 넘어 AI리터러시에 대해 이야기합니다.
2023.08.08
|
강노원
강노원
퍼실리테이팅 전문기관에서 일하다가 현재는 모두의연구소에서 교육기획자로 일하고 있습니다.
좋은 제품과 기술도 좋은 설명 없이는 확산되기 어렵습니다. 생명과학, IT부터 문화산업 전반까지 도메인에 상관없이 읽을 수 있는 글을 쓰기 위해 노력합니다.
목록으로 돌아가기
목록으로 돌아가기
공유하기
공유하기
인공지능
AI 리터러시 늘리기 : 박태웅의 AI 강의 리뷰
자기계발서는 싫지만 챗GPT와 인류의 미래는 알아야겠는 사람들을 위한 보편적이고 쉬운 책이 나왔습니다. 데이터 리터러시를 넘어 AI리터러시에 대해 이야기합니다.
2023.08.08
|
강노원
강노원
퍼실리테이팅 전문기관에서 일하다가 현재는 모두의연구소에서 교육기획자로 일하고 있습니다.
좋은 제품과 기술도 좋은 설명 없이는 확산되기 어렵습니다. 생명과학, IT부터 문화산업 전반까지 도메인에 상관없이 읽을 수 있는 글을 쓰기 위해 노력합니다.
목록으로 돌아가기
목록으로 돌아가기
공유하기
공유하기