교육
AI 교육
AI 아이펠
- AI 심화
(사전모집)
AI 코어
- AI 기초
취준생 액티브러닝 캠프
액티브러닝 캠프
(모집중)
프론트엔드 개발자
(모집중)
백엔드 개발자
(모집중)
데이터 분석가
(사전모집)
데이터 사이언티스트
(사전모집)
직장인 액티브러닝 캠프
AI/LLM 서비스 개발
- 퇴근후 2시간으로 완성
(사전모집)
온라인 강의
전체보기
인기/추천강의
(할인중)
국비지원
(내일배움카드)
커뮤니티
모두모임
- 함께 성장하는 즐거움
LAB
- 모두의 열린 연구실
페이퍼샵
- 해외 학술 논문 지원
테크포임팩트
- 임팩트 기술 커뮤니티
무료 세미나
직장인 AI
- 직장인 대상 무료 교육
모두콘 2024
- AI for Next Impact
AI 기업 교육
블로그
스토리
교육
커뮤니티
무료 세미나
AI 기업 교육
블로그
스토리
로그인
로그인
아티클
모두연 인기
인공지능
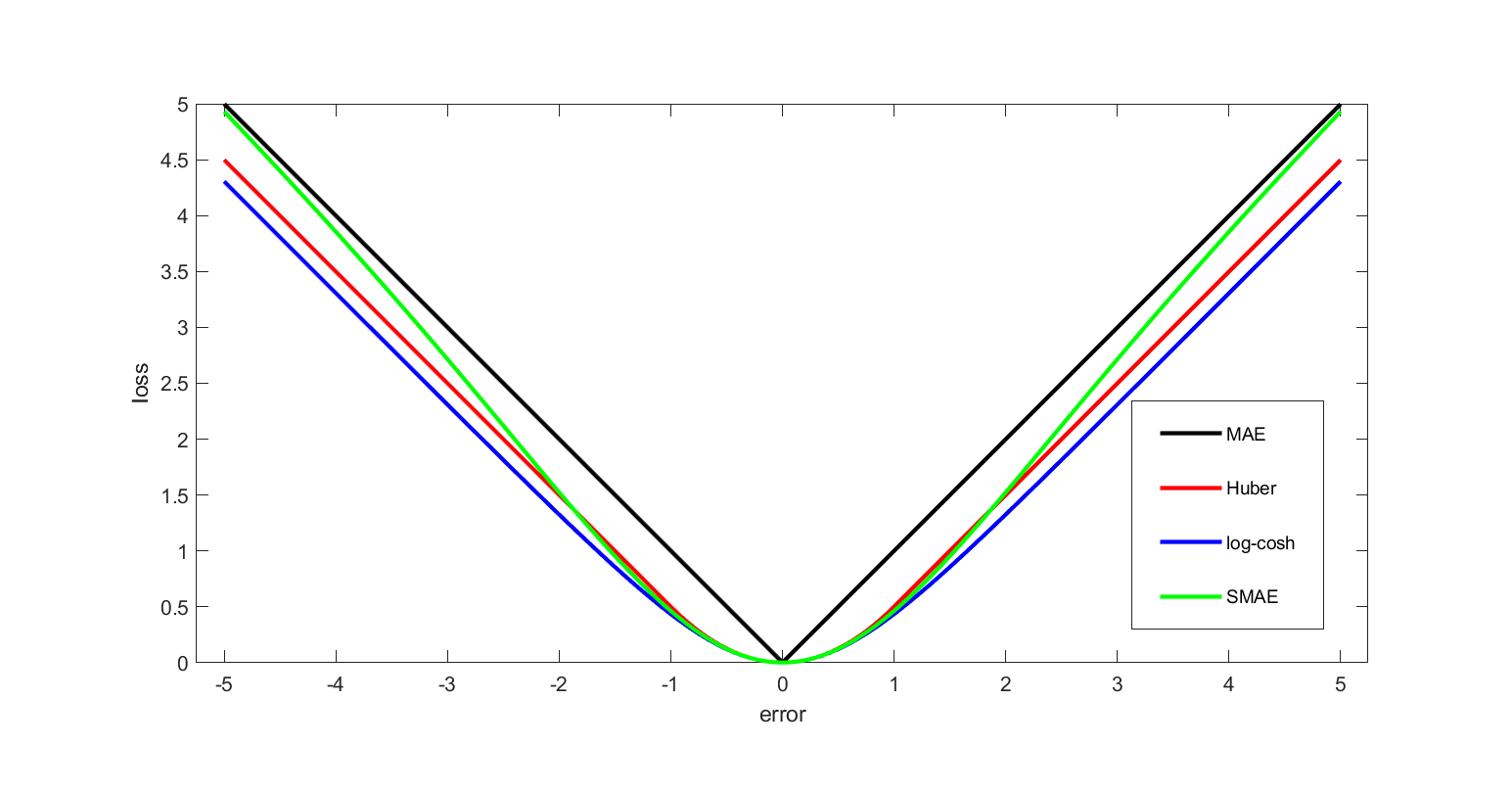
손실함수 (Loss Function)
머신러닝과 딥러닝에서 아주 중요한 개념 중 하나인 손실함수에 대해 이야기해보려고 합니다. 손실함수는 모델의 학습을 이끄는 나침반과 같은 역할을 합니다. 이번 글에서는 손실함수가 무엇인지, 어떤 종류가 있는지, 그리고 왜 중요한지 살펴보도록 하겠습니다.
2024.04.16
|
김정은
김정은
모두의연구소
모두의연구소 아이펠 퍼실리테이터
목록으로 돌아가기
목록으로 돌아가기
공유하기
공유하기
인공지능
손실함수 (Loss Function)
머신러닝과 딥러닝에서 아주 중요한 개념 중 하나인 손실함수에 대해 이야기해보려고 합니다. 손실함수는 모델의 학습을 이끄는 나침반과 같은 역할을 합니다. 이번 글에서는 손실함수가 무엇인지, 어떤 종류가 있는지, 그리고 왜 중요한지 살펴보도록 하겠습니다.
2024.04.16
|
김정은
김정은
모두의연구소
모두의연구소 아이펠 퍼실리테이터
목록으로 돌아가기
목록으로 돌아가기
공유하기
공유하기