NeRF: 2D 이미지를 3D로 바꿔준다고요?
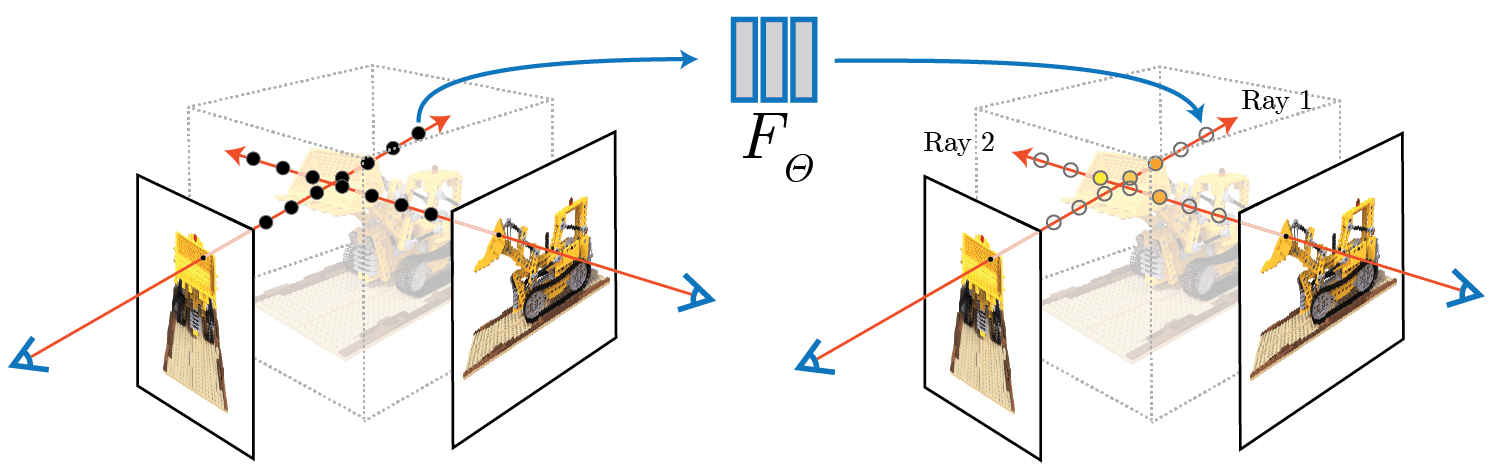
요즘 인공지능 분야에서 핫한 분야가 무엇일까요? 아마도 NERF가 아닐까 싶습니다. NeRF(Neural radiance Fields)는 2D 이미지를 3D로 변환해주는 모델입니다. 이번 콘텐츠에서는 NeRF에 대해 알아보겠습니다.
2022.11.11|박은지

박은지모두의연구소
(관심 분야) AI, Data, ML, SW, IT, Contents
🤳 프로필 이미지는 AI가 그려준 아바타입니다. (app: Voilà AI Artist Cartoon Avatar)